Ambiguity in C
Parsing Trouble: the Good, the Bad, and the Context-Sensitivity of C's Grammar

If you’ve ever written a parser for C, you’ll know the most annoying part is the ambiguities. A well-designed language should let users map their high-level, abstract intentions to concrete constructs while expressing them with as little typing as possible. For that to happen, the language constructs need to be expressive and flexible, and their grammar should ideally be simple and context-free. Ambiguities undermine this, and unfortunately, C is full of them, from declarations to expressions.
In theory, most of these could be resolved just by checking whether an identifier is a type. But that requires building a type table during parsing, which I strongly dislike for several reasons (more on that at the end). For now, I want to go through some of the ambiguities I’ve run into and how I’ve (hackily) worked around them.
1. Pointer declarations are ambiguous
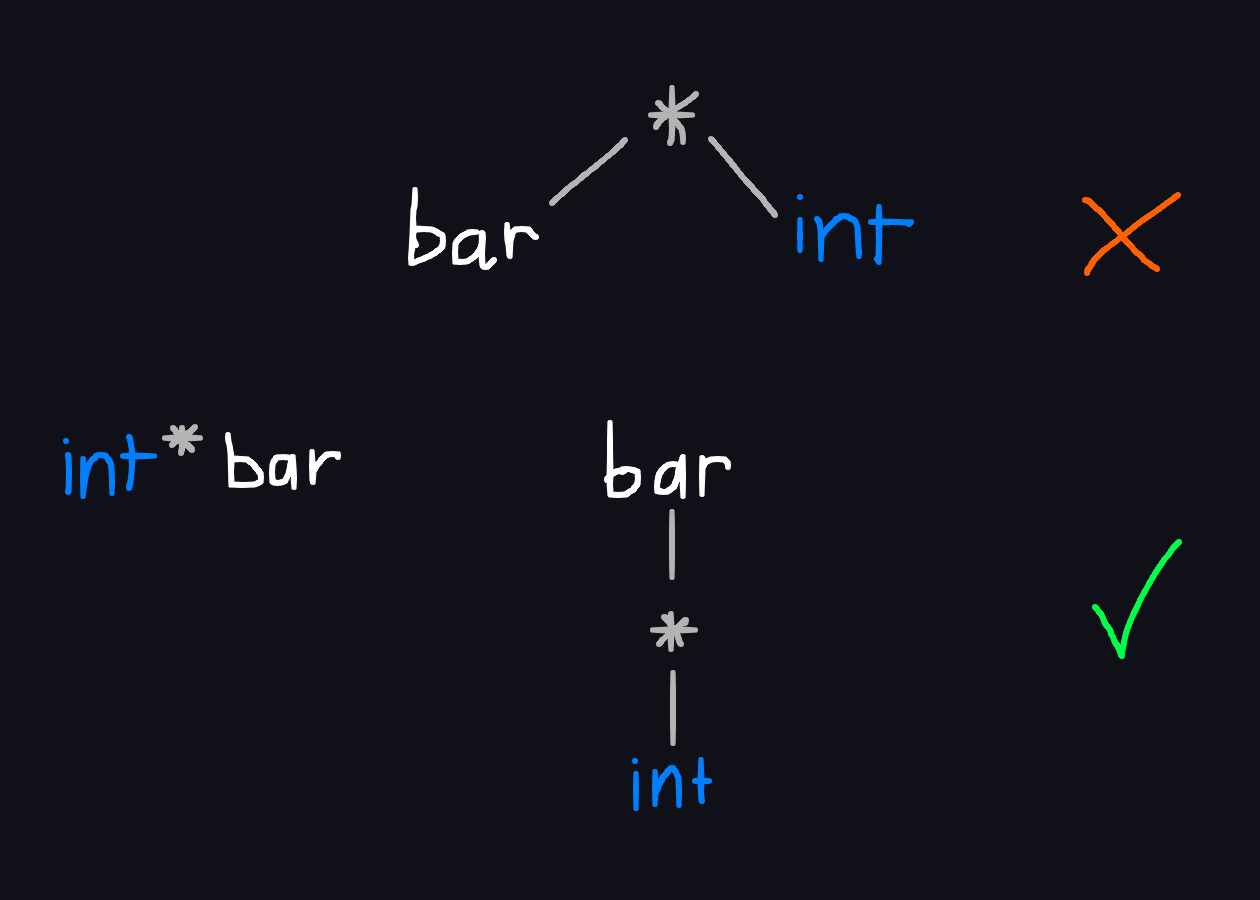
The infamous pointer declaration syntax:
foo * bar;Is the above statement a declaration or a multiplication? You can’t know for sure without checking the type table.
2. Declarations with parentheses are ambiguous
How can you differentiate between a declaration using parentheses and a function call?
foo(bar);This could either be a declaration of the variable bar with type foo (with the parentheses doing nothing), or a call to the function foo with bar.
Things get messier when you combine this with the pointer declaration syntax to declare function pointers.
foo(*bar)();This could mean that bar is a pointer to a function returning foo, or it could mean that foo is a function taking bar as a parameter and returning a function pointer. A trickier case is foo(*bar(baz))[5]. Depending on the context, this can be read either as a function declaration or as an expression involving two function calls.
3. Anonymous argument declarations are ambiguous
Most people probably know this, but C allows functions to have unnamed arguments:
int MyFunc(int a, float b, char c); // valid
int MyFunc(int, float, char); // validOn top of that, when your arguments are pointers to functions, C has a special shorthand where you don’t need parentheses around the argument’s name:
int MyFunc(int (*func)(int)); // valid
int MyFunc(int func(int)); // validPut these two features together, and you get cases like:
int MyFunc(foo (bar));Does this mean an argument named bar of type foo? Or an anonymous pointer to a function that takes bar and returns foo? It depends on whether bar is a type or not.
4. The cast operator is ambiguous
We’ve been stuck on declarations for a while, so let’s switch over to expressions. In C, a cast is just a pair of prefix parentheses, and we all know how “unambiguous” parentheses in C are.
(foo)(bar); // Is this a cast or a function call?
(foo)*bar; // Is this a cast of a dereferenced pointer, or just multiplication?And because parentheses are also valid in declarations, you can get cases like this, with three possible interpretations:
foo (*(bar)(baz))[3]; // I'll leave it to the reader as an exercise5. Polyfixic operators can be ambiguous
Here’s an interesting observation I stumbled across while writing an expression parser. C itself doesn’t have this issue, but I think it’s worth sharing anyway. It’s about the fixity of operators—whether they’re prefix, infix, postfix, etc.
Imagine you introduce an operator # that can be prefix, infix, and postfix.1 Now, what is the evaluation order of the following:
a # # b; // Is it '(a#) # b' or 'a # (#b)'? You can't tell.You run into the same ambiguity when mixing operators of different fixities. For example, if # can only be prefix or infix, and $ can be either infix or postfix, you still end up with an ambiguity:
a $ # b; // This can be either '(a$) # b' or 'a $ (#b)'.Another issue is lookahead. In an LL(1) parser, you can’t immediately tell whether an infix–postfix operator is infix or postfix without looking ahead. That’s one reason C (and most other languages) avoids them.
Dealing with ambiguity in C
In his article LL and LR in Context: Why Parsing Tools Are Hard, Josh Haberman describes three ways to deal with this problem:
Operator precedence: prefer operators with higher precedence (as defined by the language), regardless of fixity. You can always tweak this—for example, demand at least N prefixes before switching to infix, or matching the longest possible postfit.
Prioritized choice: always prefer one alternative over another. Classic examples include C++’s most vexing parse or the dangling else problem.
Semantic predicates: Turing-complete code, such as building a type table. Technically speaking, the first two are just simpler cases of this, but I want to emphasize their simplicity. You could also move in the other direction, toward a far more complex solution, especially if the language is poorly designed.
The third option is out because I don’t want to build a type table. Since C has no polyfixity problem, let’s ignore option 1. That leaves us with prioritized choices. To be clear: this doesn’t actually fix the problem. The only correct solution is to build a type table, which we’ve already decided against. All we can really do is make some heuristic guesses and hope they match the common cases.
For example, I always parse foo * bar as a pointer declaration if it appears at the beginning of a statement, since I never write a meaningless multiplication. If it’s inside an expression (e.g. a = foo * bar), then it’s multiplication, because declarations aren’t allowed inside expressions.
The same rule applies to parentheses. If it’s at the beginning of a statement and there’s nothing between foo and the opening parenthesis, I parse it as a function call. That’s because function calls are more common in practice, and most of my more complex declarations usually include a * in between.
foo (*bar[2]); // This is parsed as a function call
foo * (*bar[2]); // This is parsed as a declaration (and not an expression because of the first rule)As for anonymous function pointer arguments and the cast operator: I never use the former, and I’m still experimenting with the latter. My current plan is to add a simple check for the identifier in (foo)(bar). If foo is a single identifier, I’ll parse it as a type cast—since I never write (MyFunc)(arg). If foo is a subexpression or contains multiple identifiers, it gets trickier, because I can imagine writing something like (cond ? func1 : func2)(arg). In that case, it might be manageable to check whether the expression inside the parentheses is a type (or arithmetic) expression.
The problem with C’s grammar
Most of C’s ambiguities arise from its declaration syntax and cast operator. I believe many of these design choices made sense when C was developed. On multiple occasions, Brian Kernighan and Dennis Ritchie explained why certain syntaxes—declarations, arrays, casts, and so on—were chosen. I haven’t tracked down all of those explanations myself, so it would be helpful if a reader could clarify why a particular feature was designed that way, and what kind of parser they had in mind that made it practical. But now, more than half a decade later, we must wonder: how would a better language solve these problems?
On the Ambiguity of the Syntax of Declarations
Ginger Bill2 has written about this before, where he categorized it as 3 different styles:
Qualifier-focused (Pascal family) has specific keywords/qualifiers/specifiers for declarations
var foo = 123; const bar = “string”;Type-focused (C family) puts the type at the beginning of the declaration
int x = 123; char const* bar = “string“;Name-focused3 (Odin/JAI/etc) puts the name at the beginning of the declaration
x := 123; bar :: “string”;
Some languages use a hybrid approach. Python, for example, uses a qualifier-focused style for functions, classes, and imports, and a name-focused style for variables. In contrast, C uses an incomplete type-focused syntax for pointers and arrays: the * and [] symbols are bound to the name, not the type. Most modern C-like languages have corrected this inconsistency.
int *a, **b, c; // int *a; int **b; int c;
int* arr[10]; // declare arr as array 10 of pointer to intEach style has different pros and cons, which I won’t go into now. What I want to focus4 on is which style tends to produce more ambiguities. At first glance, you may be thinking that type-focused syntax creates more ambiguities (e.g, foo * bar), but that’s not necessarily true. For example, both of the following declarations (declare bar as a pointer to foo) are name-focussed, but with and without a colon after the name:
bar: *foo; // unambiguous
bar * foo; // ambiguousSimilarly, none of the following is ambiguous at all:
bar foo* (name-focused)
*foo bar (type-focused)
bar:*foo (name-focused)
foo*:bar (type-focused)So what truly distinguishes a declaration from an expression is either a grammar that prevents the same sequence of symbols from being valid in different contexts,5 or the use of special markers—keywords in the qualifier-focused style or symbols in the name-focused style. From my experience, I always prefer any language that has the latter. I won’t get into the reasons for now.
On the Aesthetics of the Syntax of Cast
Continuing with the categorizations we defined earlier, let’s discuss the three styles of cast syntax:
Name-focused (C family) puts the type inside the parentheses:6
(foo)bar; (foo*[10])bar;Type-focused, on the other hand, groups the name inside instead. This is also my personal favorite because it resembles a function call. Unlike declarations, where the focus is on the name, casting emphasizes the type, since it follows the concept of constructors in other languages: an operation that constructs a new instance of a type from some arguments (in this case, one). The only downside is that it doesn’t play well with pointer/array casting, or more generally, with operators. If anyone knows a solution for this, I’d love to hear it.
foo(bar); // Great foo*[10](bar); // ???Qualifier-focused uses a keyword (typically cast) and wraps either the type or both inside the parentheses.
cast(foo)bar; cast(foo*[10])bar; cast(foo, bar); cast(foo*[10], bar);The latter requires an extra comma, but it’s clearer when bar is a subexpression.
// People might be confused about the evaluation order of: cast(foo)bar + 10; // And making it clearer require an extra pair of parentheses (cast(foo)bar) + 10 cast(foo)(bar + 10) // On the other hand, these are always obvious: cast(foo, bar) + 10; cast(foo, bar + 10);
Why I hate building a type table
First of all, it’s more work. Just design your language properly instead of offloading the burden onto users. This makes the language harder to read and understand, and much more difficult to build fast compilers, editors, analyzers, and debuggers.
Secondly, a type table doesn’t make sense when you’re writing a parser for an editor to have syntax highlighting and code indexing. This is also one of the reasons I hate LSP.7 The idea of using a compiler frontend like clangd inside an editor makes no sense to me: what the compiler needs to see is irrelevant to what the user needs to see. The two kinds of parsers are fundamentally different.8
The point of a compiler is to consume syntactically and semantically valid files, while the point of an editor is to constantly invalidate those files. Every keystroke, every half-written parenthesis, every incomplete identifier will be perceived as errors by the compiler. Because of this, compiler-style parsers don’t handle half-written code well. All they can do is report an error and stop. An editor can’t work that way. It must always keep going, stitching together as much structure as it can. It can’t crash on invalid input or recursive references, and it can’t repeatedly reparse the same file with different preprocessor settings. If I #if out code, I still want it highlighted. If I shuffle the include order or compiler flags, the editor shouldn’t behave differently. And if I reuse a name while editing, the editor must show every occurrence correctly.
Because of this, a type table isn’t that useful for an editor. You want the editor to know if this particular piece of text is a declaration or not, without knowing what its type is, because the name is more important than the type. More generally, what you truly want is a name table—a hash table of identifiers the editor can use to color, navigate, and link code. A full, spec-compliant language parser is way overkill, and guarantees a lot of wasted/inefficient work for a slower and worse result. This is also why having a separate preprocessor layered on top of the base language, like C does, is a bad decision. It splits the grammar, breaks the context-free assumptions, and makes it even harder for the editor to extract the names it needs.
Thanks for reading! If you enjoyed it, consider subscribing for more.
-Trần Thành Long
I call these operators “polyfixic,” inspired by “polymorphic.”
Bill Hall, creator of the Odin programming language.
See what I did there?
It turns out that the ‘declaration reflects use’ principle is not only confusing and hard to read, but also needlessly complicates parsing. There’s even an entire website dedicated to deciphering C declarations.
The reason I consider this version name-focused is that I read this as “apply the prefix operator (…) to bar”, so my eye is anchored on bar instead of foo. As for the type-focused version, because the type is written in a “function-like” position, my eye treats it as the function name in this case, which makes it stand out compared to the name.
Using a compiler frontend is not exclusive to LSPs. Other editors and tools utilize similar mechanisms without involving any server protocol. The definition of LSP also doesn’t mandate the use of a compiler frontend, and even without it, LSPs still face other significant issues. However, in practice, most LSPs follow this trend, and people often conflate these two concepts. In my opinion, LSP represents the worst of both worlds, as it not only suffers from some fundamental problems but also faces additional challenges due to the misuse of compiler frontends in these misplaced contexts.
Editor parsing and compiler parsing are indeed different. However, there are some similar stages where deduplication makes sense. Unfortunately, this isn’t feasible in the current ecosystem, since all popular compilers are shipped and treated as black boxes. This is also one of the broader issues I previously pointed out that deserves reevaluation.
In this language, are you askin' how to maintain separate namespaces in symbol table, such that you can have foo(bar) and int(bar) be distinct, or do you want a parser lookahead type thing for it, or do you intend to have the function call syntax also be something different like the different casting is (assuming there's traditional things like function calls in this language) p.s. whats the dwelling name of the language in case we refer to it? im workin' on a custom shell called 'blush'
What if you could create a compiler that would transpile C into a strict unambiguous subset of C, which could then both be read more easily/clearly by humans, and also targeted more easily by tooling etc.?
This subset should be able to be compiled by pre-existing C compilers, of course.
I was going to suggest the name C-- or Sub-C, but both have already been taken.
The following is some excerpts from some perplexity.ai assisted research I did just now:
TLDR: Maybe SubC could work for this purpose: https://github.com/jezze/subc
C-- doesn work for this purpose. Because:
C-- is a low level portable assembly-like language intended to be emitted by compilers of higher-level (functional) languages like Haskell, and not for reading by humans. Even though C-- is a syntactical subset of C, it embodies different operational semantics and extra runtime features (guaranteed TCO, accurate GC, efficient exception handling etc.), removes some features (variadic functions, pointer syntax, and some aspects of C's type system), so it requires an intermediate transpilation step (using a trampoline approach or other transformations) to generate standard C code suitable for existing C compilers to handle correctly. So the syntax subset may be too minimalist and non-overlapping semantic-wise (i.e. not a simple subset but a distinct intermediate language).
Full C includes **complex and sometimes underspecified semantics** for features like pointer provenance, arithmetic overflow behavior, aliasing, and evaluation order, which are challenging to preserve in a minimalist subset like C--. Consequently, the semantic gaps mean that the C-- subset cannot directly and cleanly represent all idiomatic or system-level C programs without **substantial transformations and loss of fidelity**.
This underlines why the C-- subset is used primarily for specific compiler infrastructures with adapted semantics rather than as a straightforward restricted form of C aimed at broad compatibility.
Clight is a large subset of C used in formal verification contexts. But the subset may be too large.
SubC seems to be what I was thinking of: https://github.com/jezze/subc
Though it is described as intended for teaching compiler programming, and not for production use.. See the "DIFFERENCES BETWEEN SUBC (THIS VERSION) AND FULL C89" section in the readme on that url.
It is more practical to transpile C to SubC, than converting C to extremely minimalist subsets like C--, because SubC retains more expressive C features.